
Complete Pandas Tutorial: Chapter 1 - Introduction
Start your data science journey with an introduction to Pandas, DataFrames, and Series.
Gaurav Bhardwaj

Making data easier to read, preprocessing, and removing the noisy data is the Data Scientists day to day tasks. Pandas is the open-source library used by Machine Learning people for Data Analysis and Manipulation. Let's learn it in this pandas tutorial.
If you are starting your machine learning journey. You will come across the buzzword called Pandas. So In this article, you will experience the complete Pandas tutorial from Start to End.
I have divided the post into three Chapters - Chapter 1, Chapter 2, Final Chapter
Contents of Pandas Tutorial Chapter 1:
- Why we need Pandas Library.
- Introduction to Data frames and Series
- Different ways to Import a Dataset in Pandas
1. Why we need Pandas Library:
The Initial step of machine learning is to gather the data, then we need to prepare the data. So, in order to perform the Data analysis and manipulation easier we need Pandas. Internally pandas library is built on top of Numpy and Matplotlib.
When we import the data from the different sources, we may need to join them together into a single place, do some statistical data analysis, and dealing with the missing or noisy data. Pandas can do it all for you, the library is pretty helpful.
Importing the library:
import pandas as pd
2. Introduction to Data frame and Series.
Before we practically deep dive into Pandas, let's understand the data structures of Dataframe and Series.
Series:
Series is a one-dimensional array holding any one data type i.e. int, string, float, Python objects, etc.
Syntax of Series:
series = pd.Series(data= YOUR_DATA , index= INDEX)
The index plays an important role as it is the axis label of data. The length of "data" should be equivalent to the length of the index. Note It is okay, if you don't specify the index, in such case pandas will create an automatic index for you having values [0,1,2,3 .... N], where N is the length of the data.
Tips:
You can specify the Series data and index individually using a list, or you can specify the python dict which has key-value pairs, the key will represent the index, and the value will represent the data values.
Examples:
1 Way : (Series Created with Index and Data)
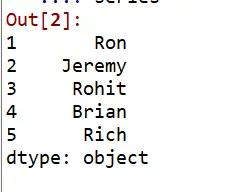
import pandas as pd list_of_names = ["Ron","Jeremy","Rohit","Brian","Rich"] roll_number = [1,2,3,4,5] series = pd.Series(data=list_of_names,index=roll_number) series
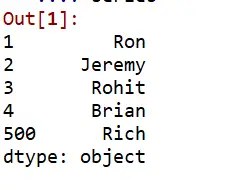
2 Way : (Series Created with dict having key as index and values as data points)
import pandas as pd
dict_of_information = {
1:"Ron",
2:"Jeremy",
3:"Rohit",
4:"Brian",
500:"Rich"
}
series = pd.Series(dict_of_information)
series
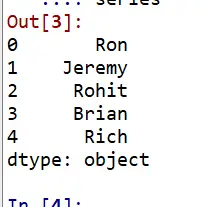
Way 3: (Series without index)
import pandas as pd list_of_names = ["Ron","Jeremy","Rohit","Brian","Rich"] series = pd.Series(data=list_of_names) series
Note: You can try out adding two series, you can see the elements having similar indexes will get added.
An example that you can try out:
import pandas as pd list_of_names_1 = ["Ron","Jeremy","Rohit","Brian","Rich"] list_of_names_l = ["Harris","Brack","Shetty","Van","Cherodio"] series1 = pd.Series(data=list_of_names) series2 = pd.Series(data=list_of_names) finalseries = series1+" "+series2 finalseries
Having a question? What if we add two series that differ in indexes. Let's try it out.
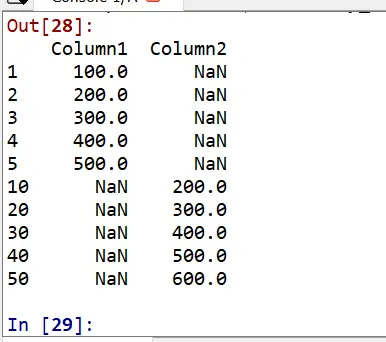
import pandas as pd list_of_numbers1 = [100,200,300,400,500] index_number1 = [1,2,3,4,5] list_of_numbers2 = [200,300,400,500,600] index_number2 = [10,20,30,40,50] series1 = pd.Series(data=list_of_numbers1,index=index_number1) series2 = pd.Series(data=list_of_numbers2,index=index_number2) series3 = series1+series2 series3
As all indexes are not the same, so the result will produce null values.
Data frames:
Dataframe is 2 dimensional labeled data structure with columns of different data types. You can think of a spreadsheet with columns and rows. Each column can hold a different data type. We can also say the Dataframes are a collection of series.
Syntax:
pd.DataFrame(data= DATA_GOES_HERE)
Example:
import pandas as pd
list_of_numbers1 = [100,200,300,400,500]
index_number1 = [1,2,3,4,5]
list_of_numbers2 = [200,300,400,500,600]
index_number2 = [10,20,30,40,50]
series1 = pd.Series(data=list_of_numbers1,index=index_number1)
series2 = pd.Series(data=list_of_numbers2,index=index_number2)
dictionary_of_series = {"Column1":series1,"Column2":series2}
df = pd.DataFrame(dictionary_of_series)
df
As you can clearly see we have passed a collection of series to data frame specifying column names.
Now you are done with the basic data structures of Pandas.
Before we head towards importing Dataset in pandas, We have a head function in data frame df.head() , which helps in returning the top 5 rows of the data frame. You can alter this "5" number say 10, you use df.head(10)
3. Different ways to Import a Dataset in Pandas
Since we have completed the basics, In the real world data we have to read the data of the various formats. So, now we will learn how to import various formats of data to a Pandas Data Frame.
Just a recap, we have series which has 1 dimension data and Dataframe has 2 dimensional labeled data with columns.
Importing a CSV File.
df = pd.read_csv("https://URLGoesHere")
Importing an Excel File.
df = pd.read_excel("https://remote_url")
Similarly, we can import the data of various formats. Different functions are available in pandas such as:
read_clipboard, read_feather, read_html, read_json, read_sas, read_sql, read_table etc.
Example:
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names)
df.head()

Congrats ! You have covered the first chapter of the Pandas Tutorial series.
If you have any comments and suggestions, please drop a comment below.
Gaurav Bhardwaj
Bridging the gap between cutting-edge AI and foundational technology. As an Engineer and AI Architect, I translate complex concepts across Generative AI, Agentic systems, and Full-stack Engineering into clear, actionable insights—all anchored by deep expertise in Linux, SEO, and systems design.


