
Apache Spark Architecture: Working and Terminologies
Explore Apache Spark architecture and core terminologies to understand how it processes data at scale.
Gaurav Bhardwaj

In this article, we will explore the Apache Spark architecture and terminologies. Before diving into the architecture let's start with the introduction & basic Terminologies of Apache Spark.
Apache spark is a beautiful framework for distributed data processing used for manipulating data at scale. Apache spark has strong support & can be coded easily by using any modern programming language like Java, Scala, Python, etc.
Spark can be easily integrated with any resource manager like YARN, MESOS, etc. Additionally, It is a highly powerful framework that makes data computations or operations at scale easier.
Interesting Facts about Apache Spark:
- First, You can easily write a code which has a potential to transform & process the data at scale.
- Spark is 100x faster than Hadoop MapReduce on memory & 10x faster on disk.
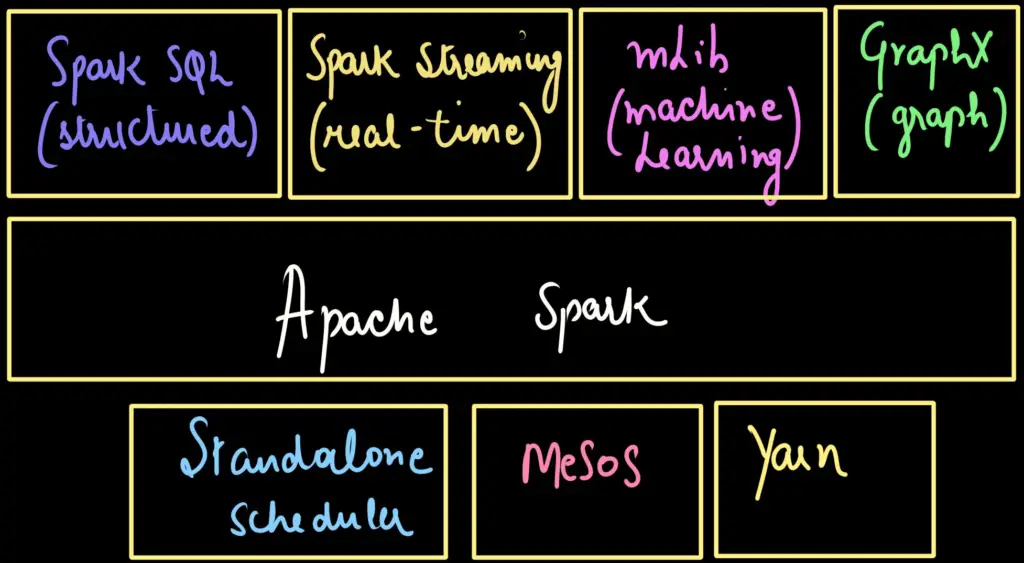
Core Concepts & Terminologies:
Before beginning the architecture, let's explore the core concepts & terminologies about Apache Spark.
1. Partitions:
A partition in spark is a logical division of the data that is stored on a disk. It is the building block of Apache Spark. The collection of partitions constitutes RDD (we will explore RDD after the core concepts).
2. Job:
A job is a code that reads the input from the HDFS or local, performs some computation on the data & returns a result.
3. Stages:
A division of Job into a unit known as a stage. Generally, the computation in spark happens in multiple stages.
4. Task:
Every stage of spark has a task associated with it. However, each task executes over one partition across an executor.
5. Execution plan:
An execution plan contains information about how execution will happen.
6. Directed Acyclic Graph or DAG:
Spark inbuilt create a DAG for optimization of the execution plan. We have covered details of DAG in the below section.
7. Task Scheduler:
A task scheduler is having great importance in the appropriate handling of resources. Moreover, it is responsible for sending tasks to the cluster manager, executing them on the cluster, and retrying on the failure.
8. Cluster Manager:
The importance of a cluster manager is to allocate and deallocate the resources on the nodes of a cluster. Some famous cluster managers are Mesos, YARN, or Spark standalone.
9. Driver Program:
A driver program is responsible for scheduling the jobs on the cluster and communicating with the cluster manager.
10. Executors:
Executors are the actual worker nodes that execute a task as scheduled by the driver program.
11. Spark Context:
A Spark context is used for setting up a connection to the Spark cluster. A spark context is generally created in a driver program & is used to create RDD, accumulator, or broadcasting variables.
We have covered all the core concepts and terminologies about Apache Spark. Now let's understand one of the important concepts of Apache Spark i.e. RDD.
RDD (Resilient Distributed Dataset):
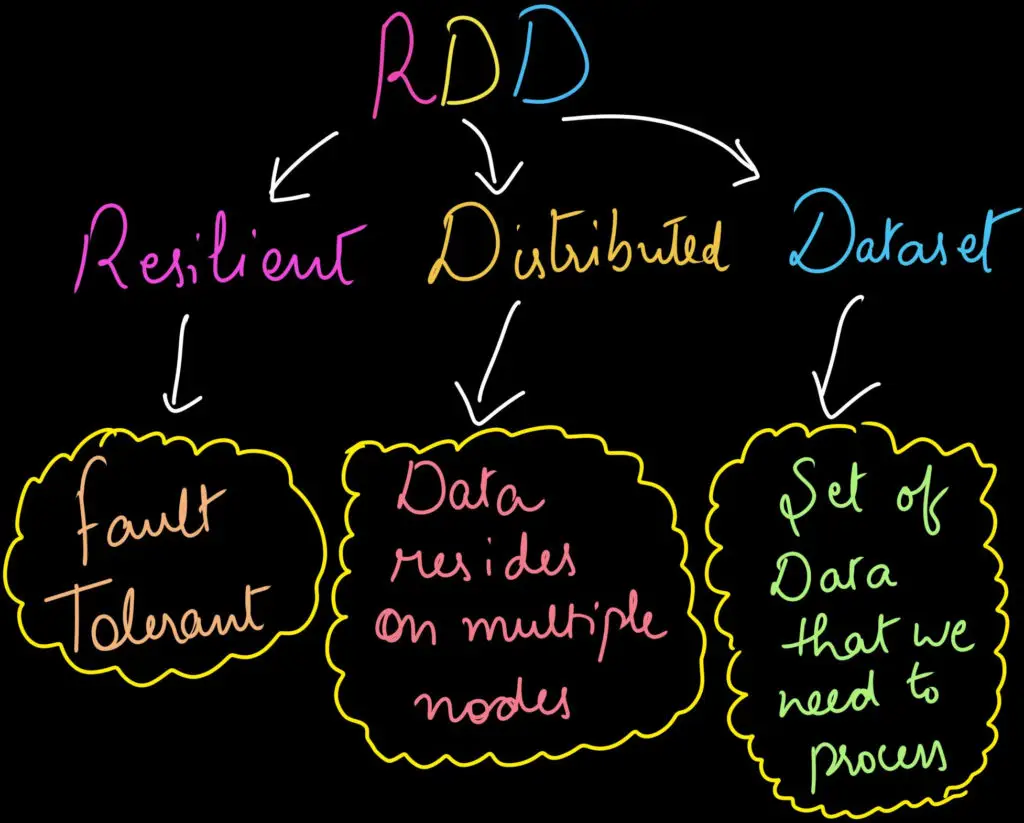
Resilient Distributed Dataset is the fundamental data structure of spark. I would say RDD is the heart of spark which is a fault-tolerant collection of elements that can be operated in parallel. RDD can also be cached & manually partitioned. Spark keeps persistent RDD in memory in default but it can also be spill to the disk in case of low RAM.
NOTE: RDD is immutable, which means you cannot change the original one.
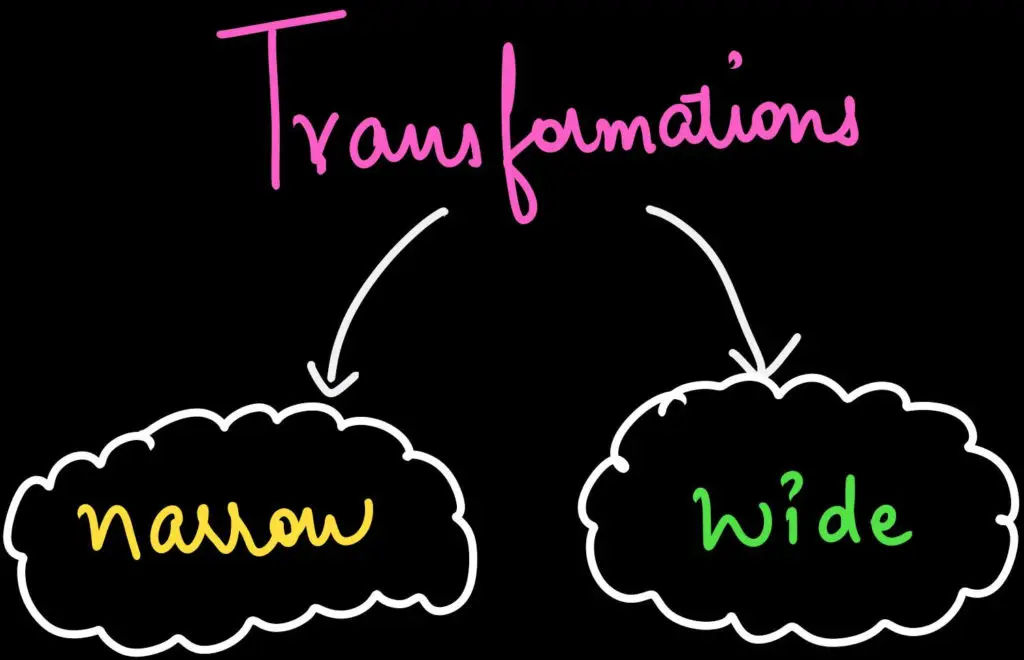
RDD supports 2 types of Operations:
- Transformations
- Actions
1. Transformations:
Transformations are the functions that take RDD as an input and return one or more RDD as an output. These are the lazy operation in RDD. Generally, it returns one or more RDD & executes when an action is encountered. Correspondingly, this is one of the elegant features of spark as it improves performance.
There are two types of transformations.
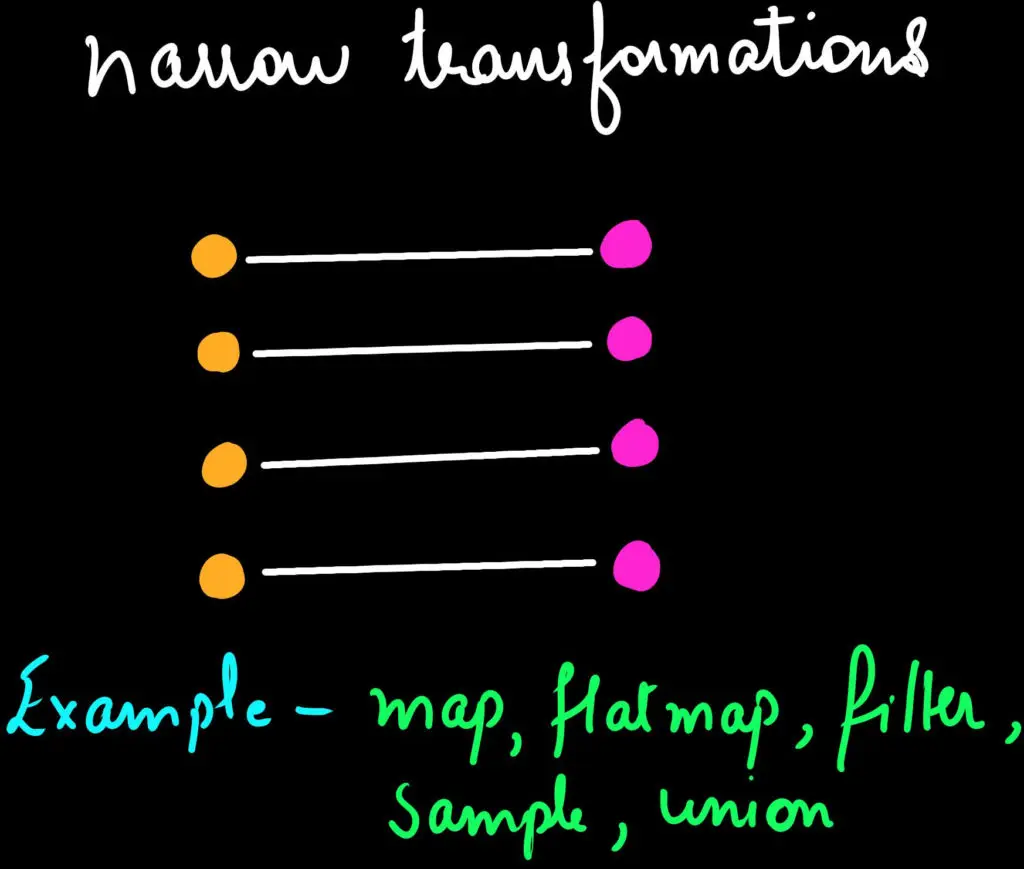
a. Narrow Transformations
In this only limited partitions are used to compute the results. In other words, An output RDD has partitions with records that originate from a single partition in the parent RDD. For Example - map, filter, etc.
Narrow transformations are always faster.
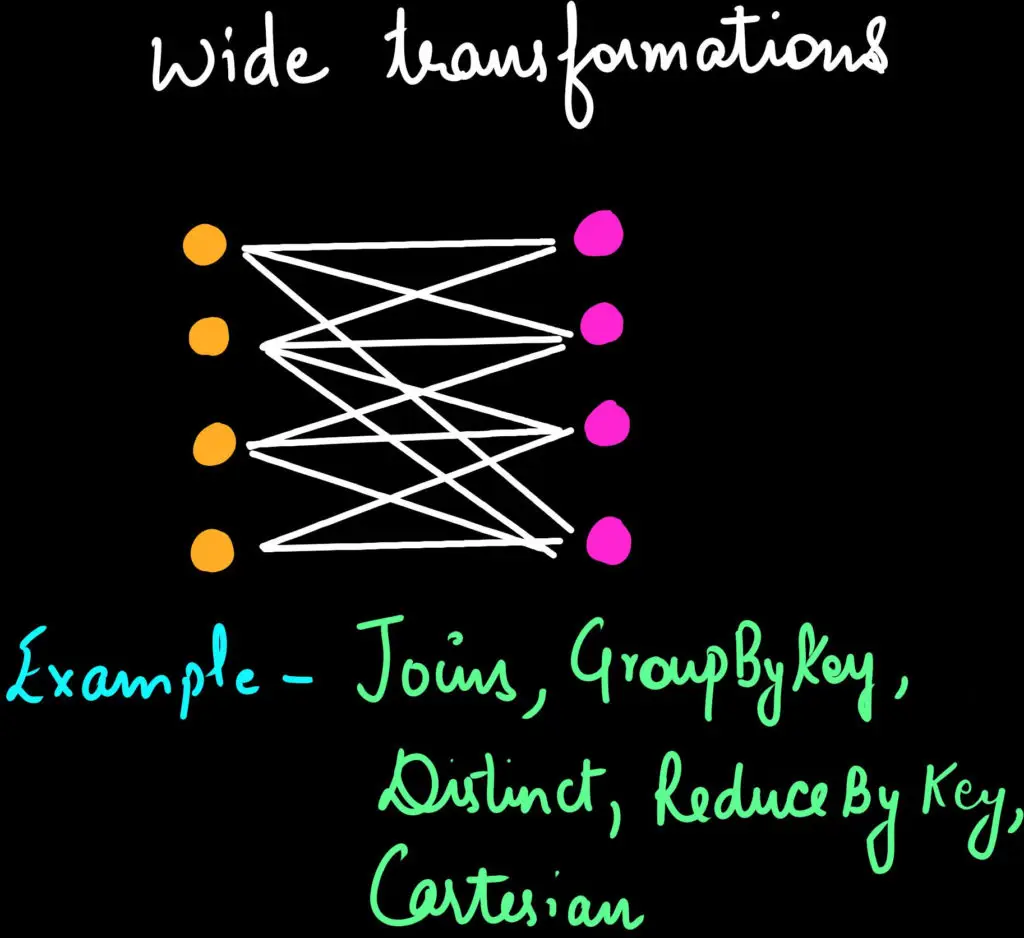
b. Wide Transformations
In wide transformation, the data required to compute the records in a single partition may reside in many partitions of the parent RDD. Hence in the case of these transformations, It might be required to shuffle data around different nodes when creating new partitions. For Example - Joins, Cartesian, etc.
Wide transformations are slower as compared to narrow transformations.
2. Actions:
As we have seen in the previous section, all of the transformations are lazy which means they do not execute right away. In contrast, actions are the functions that actually trigger the transformation execution. For Example. - count, collect, max, min, etc.
As shown in the image below, when we are applying transformations e.g. map, filter, etc, a new RDD is created. When we apply some action e.g count, reduce, max, etc. an execution occurs.
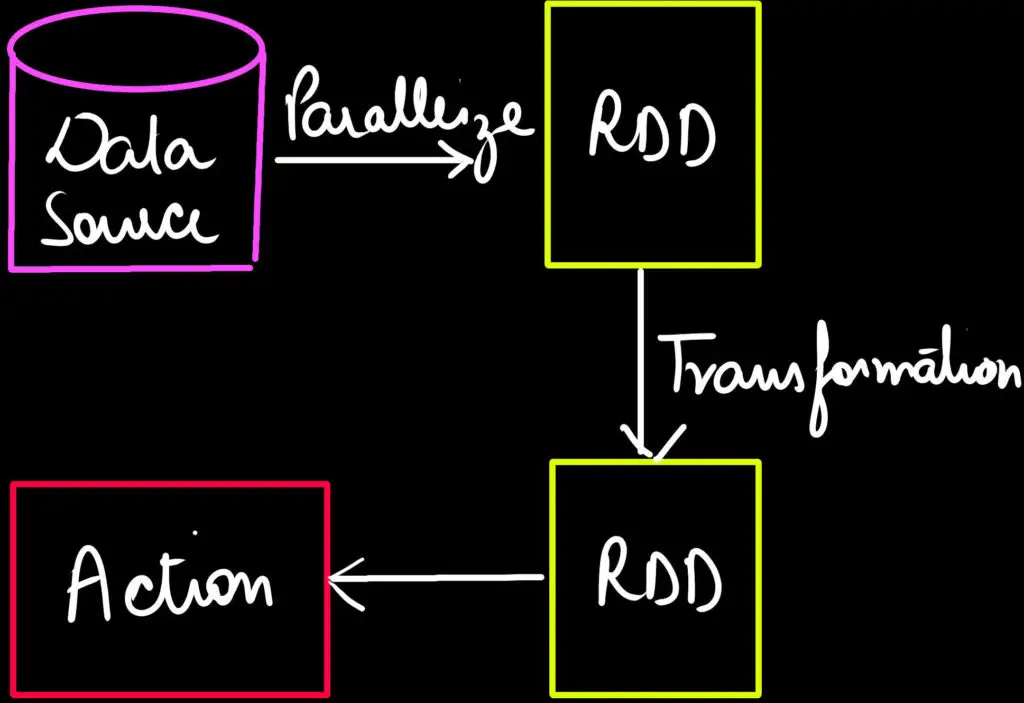
Hence, Actions are Spark RDD operations that give non-RDD values. In like manner, The values of action are stored to drivers or to the external storage system. Action is one of the ways of sending data from the Executer to the driver. As we have seen in the core concepts & terminologies that Executors are agents that are responsible for executing a task. While the driver is a JVM process that coordinates workers and execution of the task.
# The below line will find out spark
import findspark
findspark.init()
# Creating Spark Context
from pyspark import SparkContext
sc = SparkContext("local", "Demonstration App")
text_file = sc.textFile("integerlist.txt")
# Below is the transformation step - Lazy Evaluation
double = text_file.map(lambda value:value*2)
# Below is the action that triggers execution
output = counts.collect()
# Stopping Spark Context
sc.stop()
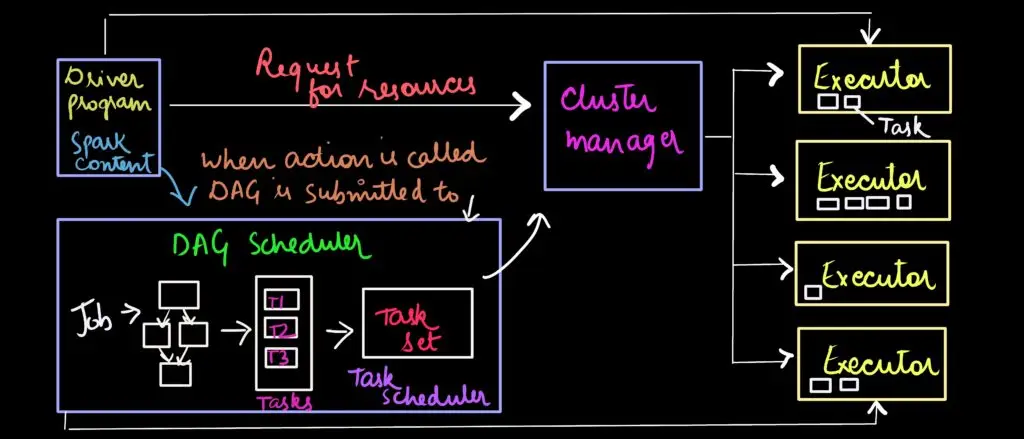
Apache Spark Architecture & Working:
We have covered the core concepts of Apache Spark, now let's understand the full architecture of Apache Spark which will give you enough insights that how Apache Spark internally works.
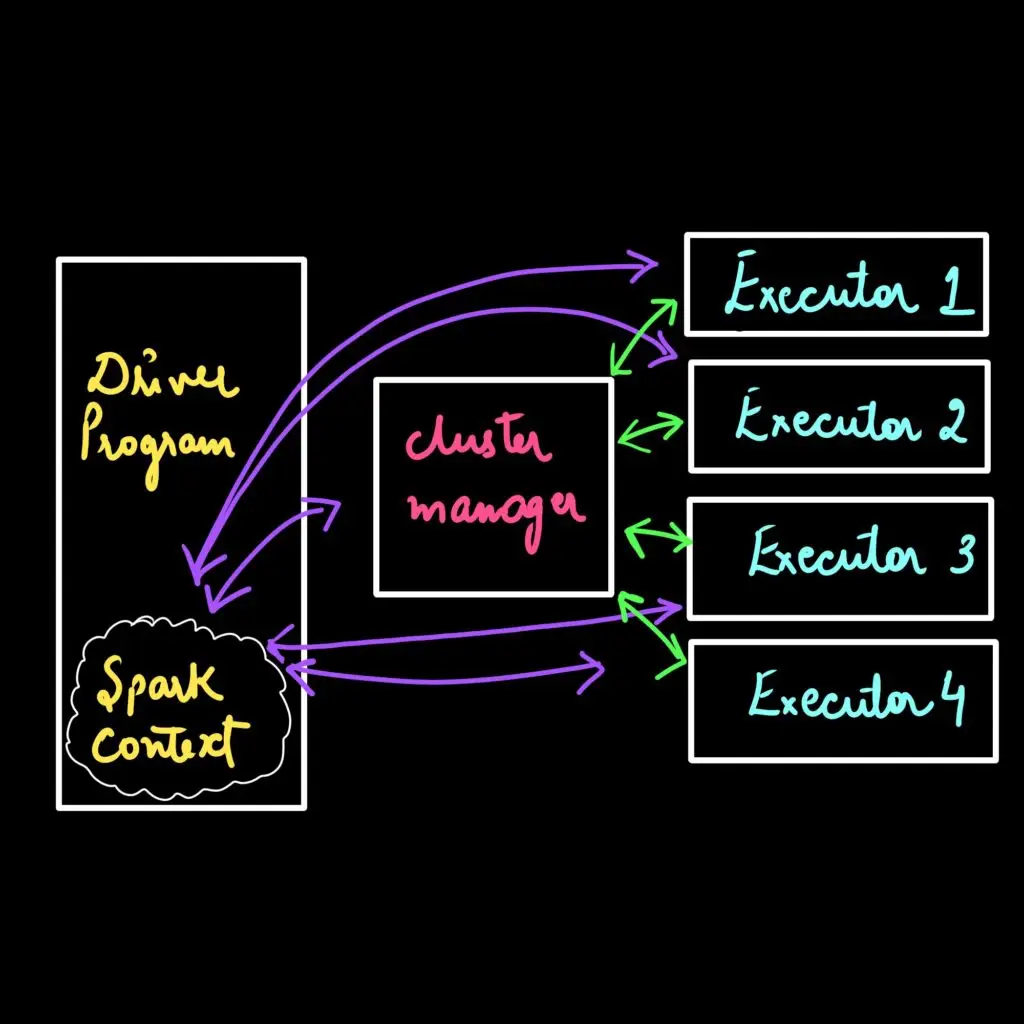
Apache spark uses master-slave architecture, one central coordinator, and many distributed workers. The central coordinator or master is also called the driver. The driver communicates with many slaves or workers, typically called executors.
Typically, when the user submits an application using spark-submit. In spark-submit, the main() method is invoked thereby launching the driver. When the job enters the driver, it converts the code into a logical directed acyclic graph (DAG).
Directed Acyclic Graph is an arrangement of edges and vertices. In this graph, vertices indicate RDDs, and edges refer to the operations applied on the RDD.
When an action of RDD is called, the created DAG is submitted to DAG Scheduler, which further divides the graph into the stages of the jobs.
In this phase, the conversion of a logical execution plan to a physical execution plan occurs. Additionally, it creates small execution units under each stage referred to as tasks. Then it collects all tasks and sends them to the cluster.
The primary responsibilities of the DAG scheduler are:
- To complete the computation and execution of stages for a job. Additionally, Keeping track of RDDs and run jobs in minimum time and assigns jobs to the task scheduler.
- Launching the tasks on executors via cluster manager.
The driver asks for the resources from the cluster manager. The cluster manager launches executors on behalf of the driver. The executors process the task and the result sends back to the driver through the cluster manager.
Example:
I hope you got enough clarity now. Let's revisit it all with a help of an example. First, let's suppose we have only the below step in our spark program.
rdd1.join(rdd2) .groupBy(�) .filter(�)
Now when the user will submit the application via spark-submit & main() method is invoked which thereby launches a driver program. A directed acyclic graph is made where the vertices are RDD & edges are the operations.
When an action is called say rdd1.collect(), the DAG is submitted to the DAG scheduler which thereby divides the graphs into stages. Furthermore, Small execution units are created under each stage and are submitted to the cluster where the cluster manager plays an important role for resources.
Refer to the diagram below:
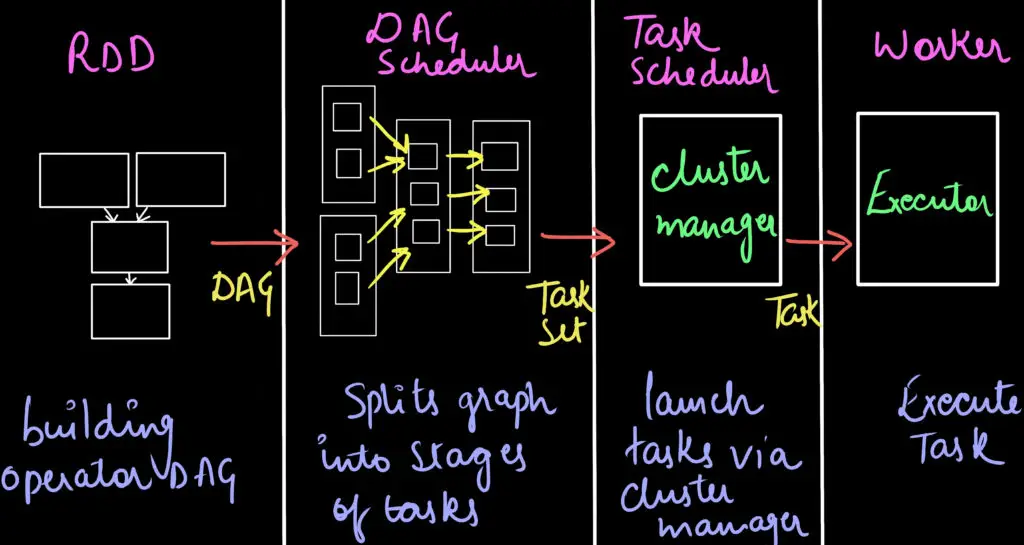
Tip: Always remember RDD -> Stages -> Tasks
Conclusion - Apache Spark Architecture Diagram:
Overall, you can refer to this diagram which clearly explains all components in Apache Spark.
Finally, That's it for this article, if you have any queries or suggestions please feel free to write in the comment section below.
Gaurav Bhardwaj
Bridging the gap between cutting-edge AI and foundational technology. As an Engineer and AI Architect, I translate complex concepts across Generative AI, Agentic systems, and Full-stack Engineering into clear, actionable insights—all anchored by deep expertise in Linux, SEO, and systems design.


