
Complete Pandas Tutorial: Chapter 2 - Dataframe Operations
Master essential Pandas DataFrame operations, including selecting, filtering, and understanding data.
Gaurav Bhardwaj

This is the second chapter of the series, "Complete Pandas Tutorial from Start to End". If you haven't seen the introductory post, I will encourage you to please do some hands-on following Chapter 1 Link.
Contents of Pandas Tutorial Chapter 2:
- Dataframe Operations for Getting a high-level understanding of Data.
- Different ways to select particular Columns, Rows and Filtering the data.
1. Dataframe Basic Methods.
As you know, In the previous chapter we learned about data frame, series data structures, and importing the dataset. Now, after importing your data, understanding the high-level data is most important. Whether you are a Kaggle competition winner or working in the top-notch MNC, high-level data understanding is done by every data scientist. Pandas have collections of functions in the data frame which provide a high-level overview of data.
Let's go back to our previous example. Importing an iris dataset in the data frame.
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names)
df.head()
For retrieving statistical information about a data frame, we have describe() function.
Syntax:
df.describe()
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names)
df.describe()
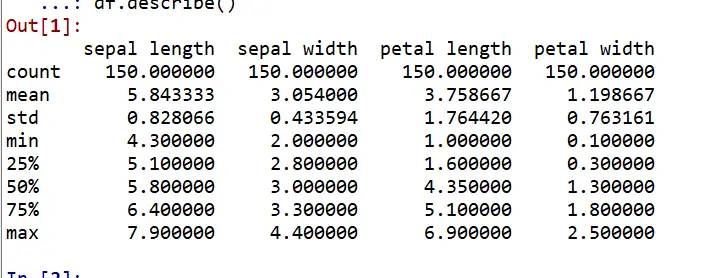
You can clearly see the high-level statistical overview of data ie. count, mean, min, max, and std of sepal length, sepal width, petal length, and petal width.
Apart from this, Some other basic functions of pandas are:
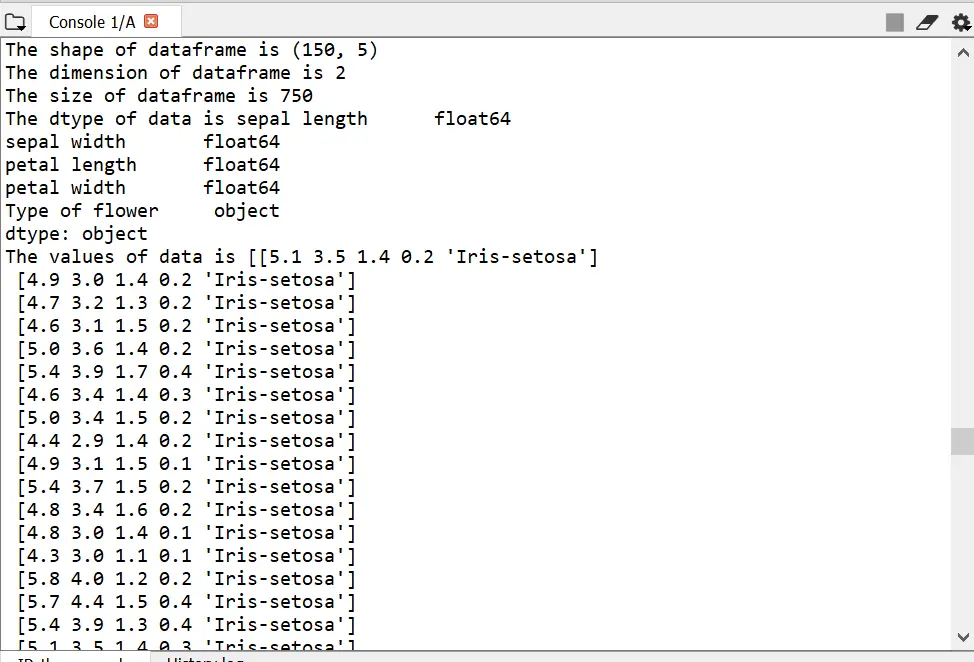
The shape method will return the tuple having dimensionality of the data frame.
The ndim method will return the dimensions of the underlying data
The size method will return the number of elements of underlying data
The dtypes method will return the data type of object
The values method will return the Series as ndarray
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names)
print("The shape of dataframe is {0}".format(df.shape))
print("The dimension of dataframe is {0}".format(df.ndim))
print("The size of dataframe is {0}".format(df.size))
print("The dtype of data is {0}".format(df.dtypes))
print("The values of data is {0}".format(df.values))
2. Different ways to select particular Columns and Rows.
Selecting Columns
In order to select a particular column in data frame, use any of the following syntax.
#1. Create a list of columns column_list = ["First","Second"] #2. Select columns in dataframe passing the column list to df df[column_list] #3. Another way using loc df.loc[:,column_list] #4 Another way using iloc (This way will accept index of columns) df.iloc[:,2:5]
Note: iloc has [:,:] i.e [START_ROW_INDEX:END_ROW_INDEX+1 and after, START_COLUMN_INDEX:END_COLUMN_INDEX+1] whereas loc has [:, List] we can select rows specifying at first and after the comma, we can pass the selected column list.
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names)
#Creating the selected column list
select_column_names=["sepal width","petal length"]
#Printing selected columns by loc way
print(df.loc[:,select_column_names].head())
#Printing selected columns by passing it in dataframe directly
print(df[select_column_names].head())
#Printing the selected columns by iloc way
print(df.iloc[:,1:3].head())

Selecting Rows:
In order to select a particular row in data frame, use any of the following syntax.
# 1. using numerical indexes - iloc df.iloc[START_INDEX:END_INDEX+1, :] # 2. using labels as index - loc (The below example will happen if the default index is used ) row_index_to_select = [0, 1, 2, 3] df.loc[row_index_to_select]
loc is used when we used labels as an index, we can directly search index searching become really fast.
Please follow the below example for better clarity.
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names)
#This will return all rows with indexes 2-4
print(df.iloc[2:5,:].head())

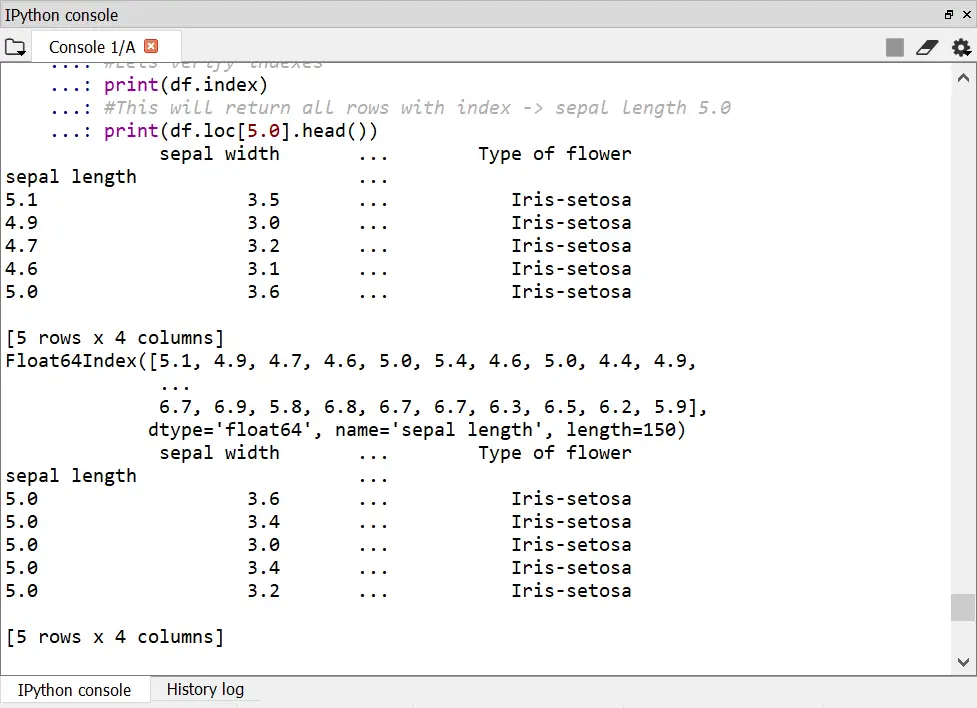
For loc, let's make sepal length as an index, and then search for the rows which as sepal length as 5.0
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names,index_col="sepal length")
#Lets see the dataframe with index as sepal length
print(df.head())
#Lets verify indexes
print(df.index)
#This will return all rows with index -> sepal length 5.0
print(df.loc[5.0].head())
Filtering data
In the real world examples, a case can arise if you have to filter out a record which is not in the index. The above methodology will help you to achieve that.
Just take an example we need to select records in the iris dataset whose petal length is greater than 5 and sepal length is greater than 6.
import pandas as pd
column_names = ["sepal length","sepal width","petal length","petal width","Type of flower"]
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
names=column_names)
df[(df['sepal length']>6) & (df['petal length']>5 )]
NOTE: Please use the brackets otherwise you will encounter error in expression.
Congrats! You have finished the second chapter. Now, you can read the final chapter.
If you have any queries or suggestions. Please leave a comment below. Will help you as soon as possible.
Gaurav Bhardwaj
Bridging the gap between cutting-edge AI and foundational technology. As an Engineer and AI Architect, I translate complex concepts across Generative AI, Agentic systems, and Full-stack Engineering into clear, actionable insights—all anchored by deep expertise in Linux, SEO, and systems design.


